Context management is very important for large models. It allows the model to provide more accurate responses based on chat history. Tencent Real-Time Communication (Tencent RTC) AI offers basic context management capabilities and also supports developers in creating their own rich context management solutions.
Basic Context Management:
Tencent RTC AI provides basic context management features. In the LLMConfig parameters, we introduce a History parameter to control context management:
History:
It is used to set the LLM's context rounds, with a default value of 0 (no context management is provided).
Maximum value: 50 (context management is provided for the most recent 50 rounds).
"History":5// Up to 50 rounds of conversations are supported, with a default value of 0.
}
Custom Context Management:
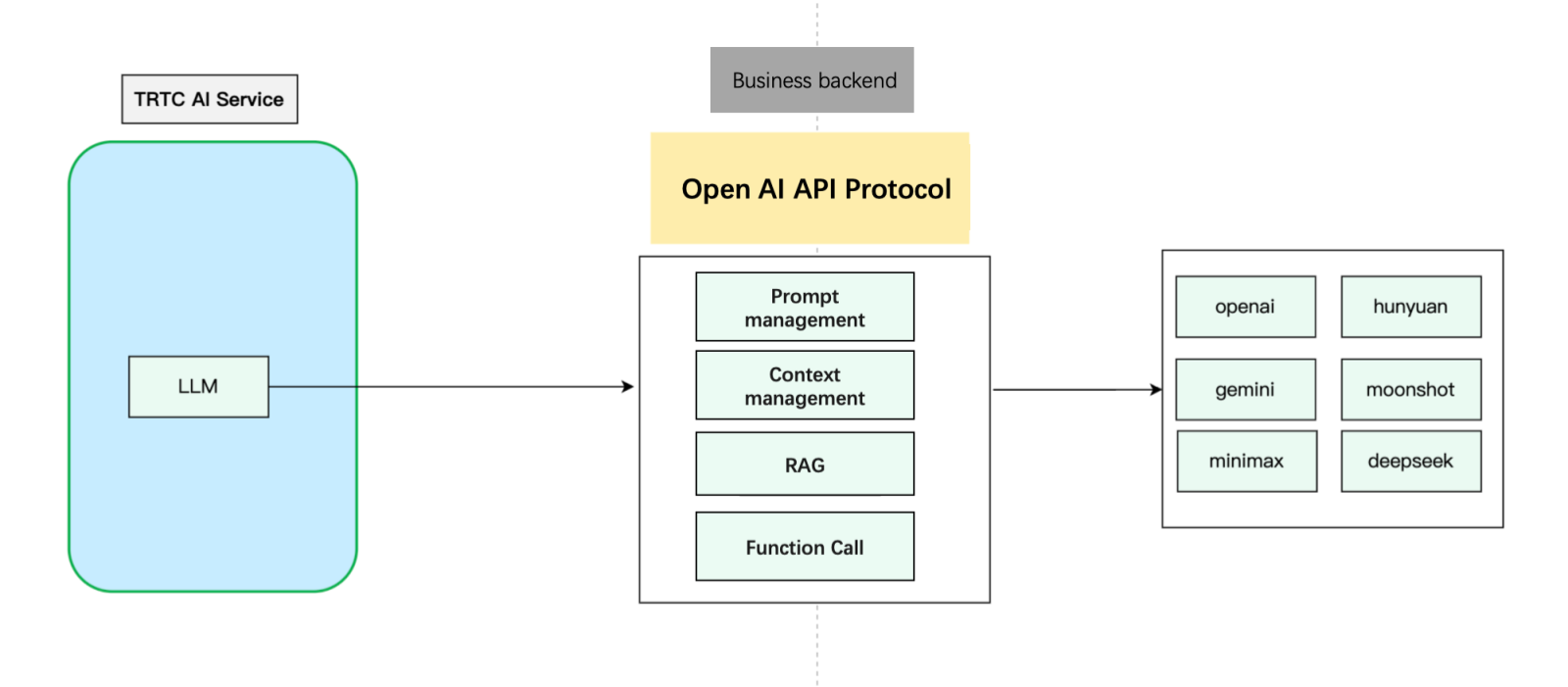
The Tencent RTC AI conversation service supports standard OpenAI specifications, allowing developers to implement customized context management in their own business. The implementation process is as follows:
This flowchart shows the basic steps for custom context management. Developers can adjust and optimize this process according to their specific needs.
Implementation Example
Developers can implement an OpenAI API-compatible large model interface at their own business backend and send large model requests encapsulated with context logic to third-party large models. Here is a simplified sample code:
importtime
from fastapi importFastAPI,HTTPException
from fastapi.middleware.cors importCORSMiddleware
from pydantic importBaseModel
from typing importList,Optional
from langchain_core.messages importHumanMessage,SystemMessage
from langchain_openai importChatOpenAI
app =FastAPI(debug=True)
# Add CORS middleware.
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
classMessage(BaseModel):
role: str
content: str
classChatRequest(BaseModel):
model: str
messages:List[Message]
temperature:Optional[float]=0.7
classChatResponse(BaseModel):
id: str
object: str
created:int
model: str
choices:List[dict]
usage: dict
@app.post("/v1/chat/completions")
async def chat_completions(request:ChatRequest):
try:
# Convert the request message totheLangChain message format.