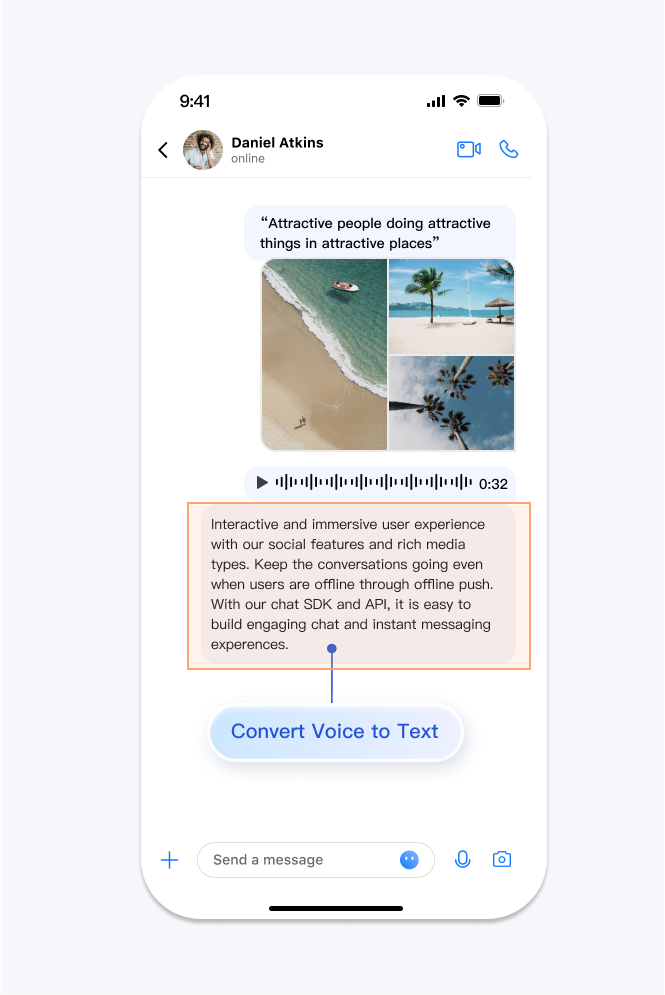
The Voice-to-Text feature can recognize your sent or received successfully voice messages, and convert them into text.
Note:
Voice-to-Text is a value-added paid feature, currently in beta. You can contact us through the Telegram Technical Support Group to enable a full feature experience.
This feature is supported only by the Enhanced SDK v7.4 or later.
Display Effect
You can use this feature to achieve the text conversion effect shown below:
API Description
Speech-to-Text
You can call the convertVoiceToText (Java/ Swift / Objective-C / C++) interface to convert voice into text.
The description of the interface parameters is as follows:
Input Parameters
Meaning
Description
language
Identified Target Language
1. If your mainstream users predominantly use Chinese and English, the language parameter can be passed as an empty string. In this case, we default to using the Chinese-English model for recognition.
2. If you want to specify the target language for recognition, you can set it to a specific value. For the languages currently supported, please refer to Language Support.
callback
Recognition Result Callback
The result refers to the recognized text.
Warning:
The voice to be recognized must be set to a 16k sampling rate, otherwise, it may fail.
Below is the sample code:
Java
Swift
Objective-C
C++
// Get the V2TIMMessage object from VMS
V2TIMMessage msg = messageList.get(0);
if(msg.elemType == V2TIM_ELEM_TYPE_SOUND){
// Retrieve the soundElem from V2TIMMessage
V2TIMSoundElem soundElem = msg.getSoundElem();
// Invoke speech-to-text conversion, using the Chinese-English recognition model by default