








Building a Doc Chat API: Integrating LLMs and RAG into Real-Time Communication

The convergence of Large Language Models (LLMs) and real-time communication demands a new architectural approach: the Doc Chat API. This technology is essential for grounding generative AI in proprietary knowledge using Retrieval-Augmented Generation (RAG). RAG utilizes vector databases to query documents, ensuring accurate, contextual responses, often managed via frameworks like LangChain. The primary technical challenge is delivering the LLM’s response back to the user with minimal latency. Tencent RTC provides the necessary low-latency, persistent layer to stream these generated responses in real time, enabling seamless voice and text interactions and creating a professional, efficient conversational AI experience.
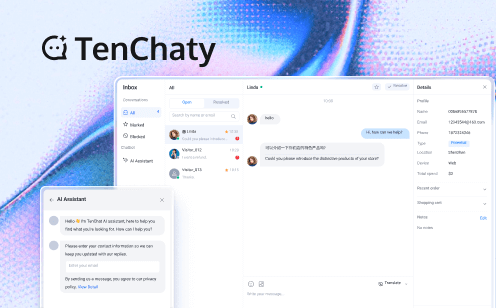
The integration of Generative AI into applications has created a demand for sophisticated Doc Chat APIs, enabling users to query internal documentation or specific knowledge bases in real-time. This functionality relies on specialized architectures that bridge the gap between traditional chat systems and large language models.
The Shift to Conversational AI: Integrating LLMs into Real-Time Interfaces
Modern conversational AI requires the ability to handle continuous, low-latency streams of multimodal input (audio, video, or text) and deliver immediate, human-like responses. For these voice agents and AI assistants, the underlying communication infrastructure must be capable of transferring data with minimal delay to create a truly "natural conversational experience".
The RTC backbone, provided by platforms like TRTC, is critical here, not as the AI engine itself, but as the high-speed delivery mechanism. When an LLM processes a query, the RTC layer ensures that the textual or audio output is streamed back to the user interface efficiently, maintaining the low latency required for production workloads that demand predictable performance.
Retrieval-Augmented Generation (RAG) Architecture and Implementation
To ensure that chatbots provide relevant, factually accurate answers grounded in specific documents (rather than relying only on generalized training data), the Retrieval-Augmented Generation (RAG) architecture is employed. RAG involves indexing proprietary documentation using embedding models, storing them in a vector database, and then retrieving relevant text snippets to provide context to the LLM during query time. This process significantly enhances accuracy and prevents hallucinations.
Developers commonly utilize AI frameworks like LangChain to manage this pipeline, linking the LLM client, conversational memory (to maintain context across turns), and the retrieval chain. Integrating this pipeline into a real-time chat interface requires seamless API interfacing—often requiring asynchronous REST API calls to the LLM provider, followed by streaming the results back through the persistent WebSocket connection to the user.
Using TRTC for Low-Latency Front-end Delivery of AI Responses
TRTC’s primary value in the Doc Chat context is providing the robust communication layer essential for performance. If an LLM response is delivered via a simple, synchronous HTTP call, the user interface may experience noticeable lag. TRTC’s real-time capabilities ensure that LLM outputs can be continuously streamed to the user with minimal delay, mirroring the immediate feel of a human conversation.
Furthermore, TRTC can support complex agent orchestration. The chat system acts as an agent, using LLM-directed "tool calling" to execute external functions—such as querying a REST API for real-time data (e.g., waiting times, order status) or accessing the document knowledge base—and efficiently integrating the tool's output back into the conversation state. This allows developers to build sophisticated, data-aware chatbots without extensive custom middleware.
Proposed Q&A
Q: What are the main components required for a RAG-based Doc Chat system?
A: Key components include the proprietary documentation, an embedding model, a vector database, an LLM (such as OpenAI or Gemini), a retrieval chain (like LangChain), and a low-latency chat interface.
Q: How can I integrate my custom REST API tools with an LLM in a chat environment?
A: This is achieved through tool calling or function calling, where the LLM decides, based on the user prompt, to execute a pre-defined function (a REST API wrapper) to retrieve external, real-time data before generating a final response.
Q: Why is low-latency communication important for conversational AI agents?
A: Low latency is crucial to provide a "natural conversational experience." If the AI’s response is delayed, the user perceives the system as slow or unreliable, leading to frustration and disengagement.
Q: Does TRTC provide native support for streaming LLM responses?
A: TRTC provides the low-latency, real-time messaging infrastructure (often based on WebSockets) necessary to efficiently stream text output generated by LLMs back to the client interface as it is created.
Q: What is the role of vector databases in a Doc Chat application?
A: Vector databases store the numerical representations (embeddings) of proprietary documents. The RAG system queries this database to retrieve relevant context, which is then passed to the LLM to ground its response in specific, factual data.