








OpenAI is indeed an amazing company. It caused an explosion from the first launch of GPT, shocking everyone with the power of AI. In fact, until today, almost all new large models use ChatGPT as a reference. Whether it is fact or propaganda, they basically say "on par with GPT" and "better than GPT". And OpenAI has indeed been controversial. In the always criticized toothpaste-squeezing propaganda method, changing management and other voices, every time everyone loses patience with it, it launches unexpected new products every time, shocking everyone again, as if only it can bring people a "boom" of surprise.
On Sep 12th, OpenAI released a new model called OpenAI o1, which is also the previously rumored "Strawberry".
OpenAI CEO Sam Altman called it "the beginning of a new paradigm".
From the official information of OpenAI, the characteristics of o1 can be summarized as: bigger, stronger, slower and more expensive.
Through reinforcement learning, OpenAI o1 has made significant progress in reasoning ability. The R&D team observed that the performance of the o1 model gradually improved with the extension of training time (increase in reinforcement learning) and thinking time (computation during testing). The challenges faced by the expansion of this method are very different from the pre-training limitations of large language models (LLMs).
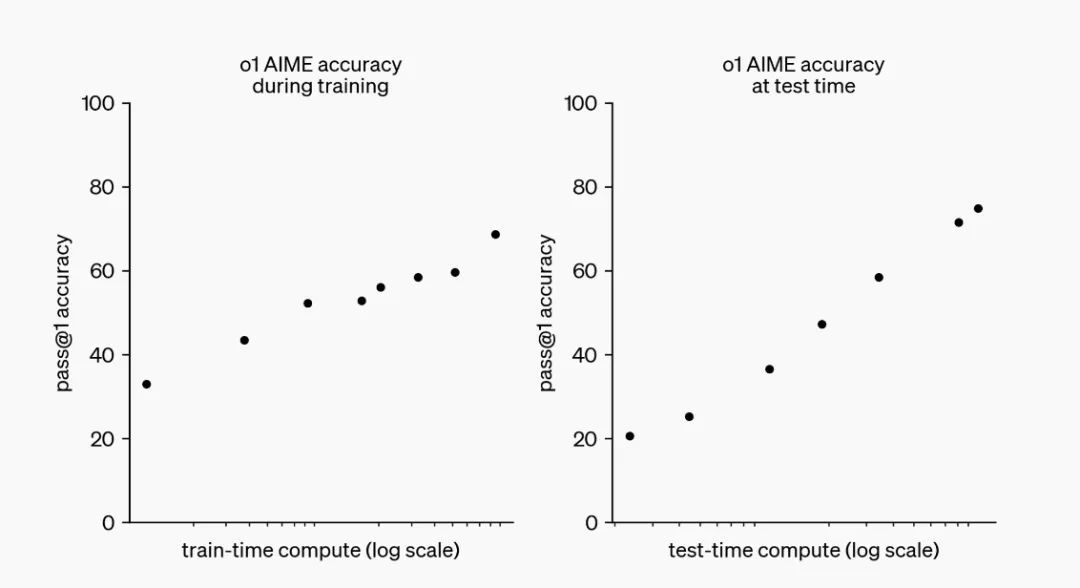
OpenAI o1 performance steadily improves with training time and test time calculation, source: OpenAI
How to understand the reasoning ability of OpenAI o1
Regarding the rumor on the market that "o1 model can autonomously perform browser or system operation level tasks for users", the current public information does not mention this function.
OpenAI officials said: "Although this early model does not have functions such as searching for information on the Internet, uploading files and pictures, it has made significant progress in solving complex reasoning problems, which represents a new level of artificial intelligence technology. So we decided to give this series a new starting point and named it OpenAI o1." It can be seen that the main application of o1 is still focused on problem solving and analysis through text interaction, rather than directly controlling the browser or operating system.
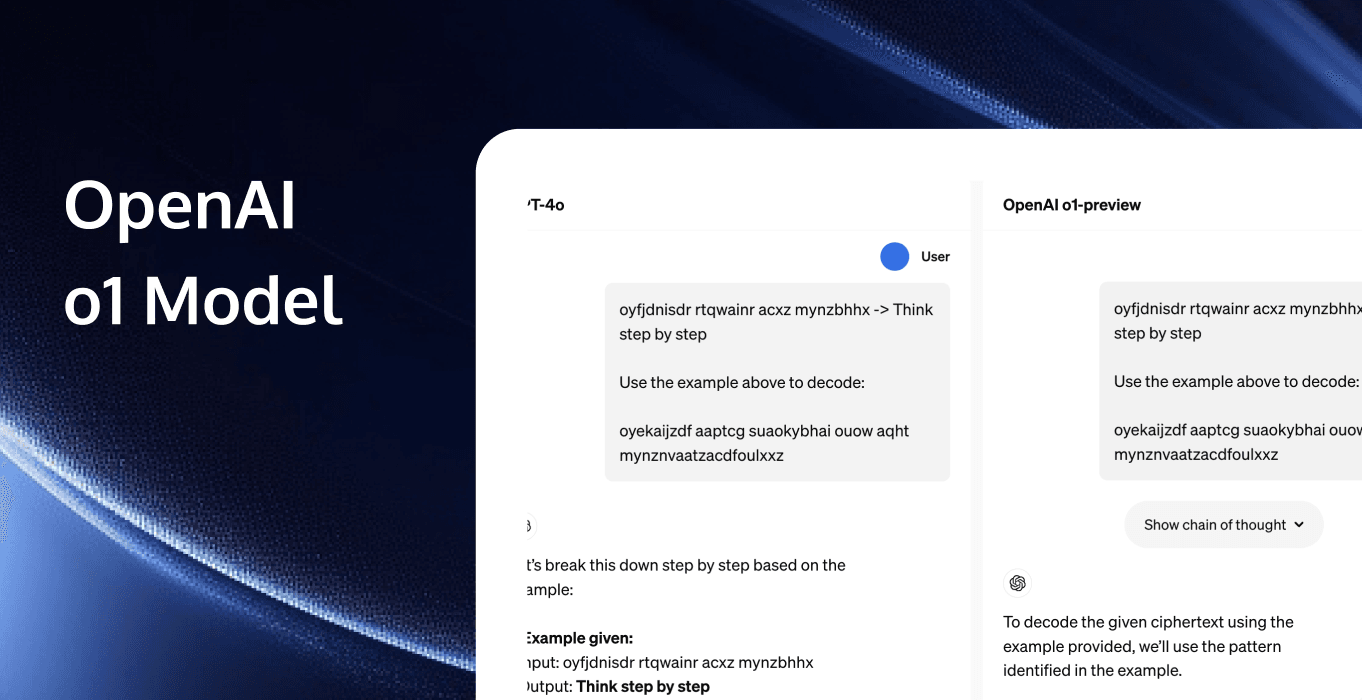
Unlike earlier versions, the o1 model "deliberates" like a human before answering, taking about 10-20 seconds to generate a long internal chain of ideas, and is able to try different strategies and identify its own mistakes.
This powerful reasoning ability gives o1 a wide range of application potential in multiple industries, especially complex science, mathematics, and programming tasks. When dealing with physics, chemistry, and biology problems, o1's performance is even comparable to that of doctoral students in the field. In the qualifying exam for the International Mathematical Olympiad (AIME), o1's accuracy rate was 83%, successfully entering the ranks of the top 500 students in the United States, while the accuracy rate of the GPT-4o model was only 13%.
OpenAI provides some specific use cases, such as medical researchers can use o1 to annotate cell sequencing data; physicists can use o1 to generate complex mathematical formulas required for quantum optics; software developers can use it to build and execute complex multi-step workflows, etc.
In other words, on the benchmark GPQA-diamond for testing chemistry, physics, and biology expertise, o1's performance comprehensively surpassed human doctoral experts, which is also the first model ever to achieve this achievement. The cornerstone of the whole model is Self-play RL. Through Self-play RL, o1 learned to hone its thinking chain and improve the strategies it used. It learned to identify and correct its own mistakes. It also learned to break down complex steps into simpler steps. And when the current method does not work, it also learned to try different methods. What he learned is the core way of thinking for us humans: slow thinking.
Daniel Kahneman, Nobel Prize winner in economics, has a book called: Thinking, Fast and Slow. It explains the two ways of thinking of humans in great detail.
The first is fast thinking (system 1), which is characterized by fast, automatic, intuitive, and unconscious. Here are a few examples:
- Seeing a smiling face, you know that the other person is in a good mood.
- 1+1=2 is a simple calculation.
- Immediately step on the brakes when encountering a dangerous situation while driving.
These are fast thinking, that is, the ability to react quickly learned by rote learning behind the traditional big model.
The second is slow thinking (system 2), which is characterized by slowness, effort, logic, and consciousness. Here are a few examples:
- Solve a complex math problem.
- Fill out your tax return.
- Weigh the pros and cons and make important decisions.
This is slow thinking, the core of our human strength, and the cornerstone of AI's path to AGI.
Now, o1 has finally taken a solid step and has the characteristics of human slow thinking. Before answering, it will repeatedly think, disassemble, understand, and reason, and then give the final answer.
To be honest, these enhanced reasoning abilities are absolutely extremely useful when dealing with complex problems in science, coding, mathematics and similar fields.
o1 is also definitely a new generation of data flywheel. If the answer is correct, the entire logic chain will become a small data set of training examples with positive and negative rewards. With OpenAI's user level, the speed of future evolution will only be more terrifying.
When can we use 3 models: OpenAI o1, o1-previewa and o1-mini
The o1 series includes three models, OpenAI o1, OpenAI o1-preview and OpenAI o1-mini. The latter two models will be open to users from September 12:
- OpenAI o1: Advanced reasoning model, not open to the public for the time being.
- OpenAI o1-preview: This version focuses more on deep reasoning processing and can be used 30 times per week.
- OpenAI o1-mini: This version is more efficient and cost-effective, suitable for coding tasks, and can be used 50 times per week.
How to use OpenAI o1
o1-preview and o1-mini have been gradually opened to all ChatGPT Plus and Team users, and will be considered to be opened to free users in the future.
Currently, all previous functions are not supported, that is, there is no image understanding, image generation, code interpreter, web search, etc., only a bare model that can be used for dialogue.
o1-mini is faster, smaller and cheaper, and it is good at reasoning. It is extremely suitable for mathematics and code, but the world knowledge will be much worse, which is suitable for scenarios that require reasoning but do not require extensive world knowledge. The o1 preview version has 30 items per week, and the o1-mini has 50 items per week.
It can also be seen from the side that the o1 model is very expensive. For developers, it is only open to level 5 developers who have paid $1,000, and is limited to 20 times per minute. It is quite small. And the function is castrated a lot, but after all, it is early, understandable. In terms of API prices, the o1 preview version costs $15 per million inputs and $60 per million outputs. o1-mini will be cheaper, at $3 per million inputs and $12 per million outputs. The output cost is four times the inference cost, compared to GPT4o, which is $5 and $15 respectively. o1-mini still has some economic effect, but it's still a start, waiting for OpenAI to make a big difference later.
ChatGPT Pro Pricing
Developers and researchers can now access these models through ChatGPT and application programming interfaces.
As for the price, The information broke the news earlier that OpenAI executives were discussing the proposed price of its upcoming new large models "Strawberry" and "Orion" at $2,000 per month, which triggered a lot of complaints and condemnations. But today, someone found that ChatGPT Pro membership has been launched, priced at $200/month. The gap from $2,000 to $200 makes it difficult for people not to feel like they are "getting a bargain", and the price psychological warfare is clearly played by OpenAI.
In May this year, Altman mentioned in a fireside chat with MIT President Sally Kornbluth that GPT-5 may separate data from the reasoning engine.
"GPT-5 or GPT-6 can be the best reasoning engine. At present, the only way to achieve the best engine is to train a lot of data." Altman believes that in fact, the model wastes a lot of data resources when processing data. For example, GPT-4. It can also work like a database, but the reasoning speed is slow, the cost is high, and the effect is "unsatisfactory." These problems are essentially due to the waste of resources caused by the design and training methods of the model.
"Inevitably, this is a side effect of the only way we can make reasoning engine models." The new method he can foresee in the future is to separate the model's reasoning ability from the need for big data.
But in today's release, GPT-5 did not appear, and the idea of separating data from the reasoning engine was nowhere to be seen.
As for the price, The Information reported earlier that OpenAI executives plan to set the price of the new large models "Strawberry" and "Orion" at $2,000 per month, which triggered a lot of complaints and condemnation. But today, someone found that ChatGPT Pro has been launched and is priced at $200 per month.
The gap from $2,000 to $200 makes it difficult for users not to feel that they are "getting a bargain". The price psychological warfare is clearly played by OpenAI.
Why is OpenAI o1’s reasoning ability different from other large models?
Large models have always been criticized for their "inability to count". The root cause is that large models lack the ability to reason in a structured manner.
Reasoning is one of the core capabilities of human intelligence. Large models are mainly trained through unstructured text data, which usually includes news articles, books, web page texts, etc. Text is a natural language form and does not follow strict logical or structured rules, so the model mainly learns how to generate language based on context, rather than how to reason logically or follow fixed rules to process information.
But many complex reasoning tasks are structured.
For example, logical reasoning, mathematical problem solving, or programming. If we want to get out of a maze, we need to follow a series of logical and spatial rules to find the exit. This type of problem requires the model to understand and apply a series of fixed steps or rules, but this is exactly what most large models lack.
Therefore, although models such as ChatGPT and BARD can generate seemingly reasonable answers based on training data, they are actually more like "stochastic parroting". They often cannot really understand the complex logic behind or perform advanced reasoning tasks.
You should know that large models perform well when processing unstructured natural language texts, which is the focus of training data. But when it comes to tasks that require structured logical reasoning, they often have difficulty performing as accurately as humans.
To solve this problem, OpenAI thought of using Chain of Thought (CoT) to "break the game".
Chain of Thought is a technology that helps AI models reason. It allows the model to explain each step of the reasoning process step by step when answering complex questions, rather than giving the answer directly. Therefore, when the model answers questions, it is like humans solving problems, thinking about the logic of each step first, and then gradually deriving the final result.
However, in the process of AI training, manually labeling thought chains is time-consuming and expensive, and the amount of data required under the dominance of scaling laws is basically an impossible task for humans.
At this time, reinforcement learning becomes a more practical alternative.
Reinforcement learning allows the model to learn by itself through practice and trial and error. It does not require manual labeling of each specific step, but optimizes the problem-solving method through continuous experimentation and feedback.
Specifically, the model adjusts its behavior according to the results (good or bad) of the actions taken in the process of trying to solve the problem. In this way, the model can autonomously explore multiple possible solutions and find the most effective method through continuous trial and error. For example, in a game or simulation environment, AI can continuously optimize strategies through self-playing, and eventually learn how to accurately perform complex tasks without manual guidance of each step.
For example, AlphaGo, which swept the Go world in 2016, combined deep learning and reinforcement learning methods, continuously optimized its decision-making model through a large number of self-playing games, and finally defeated the world's top Go player Lee Sedol.
The o1 model uses the same method as AlphaGo to gradually deal with problems. In this process, o1 continuously improves its thinking process through reinforcement learning, learns to identify and correct errors, breaks down complex steps into simpler parts, and tries new methods when encountering obstacles. This training method significantly improves o1's reasoning ability, allowing o1 to solve problems more effectively.
Greg Brockman, one of the co-founders of OpenAI, is "very proud" of this. "This is the first model we have trained using reinforcement learning," he said.
Screenshot of Greg Brockman's tweet, source: X
Brockman introduced that OpenAI's model originally performed system-type 1 thinking (fast, intuitive decision-making) and the thinking chain technology activated system-type 2 thinking (careful, analytical thinking).
System-type 1 thinking is suitable for quick response, while system-type 2 thinking uses the "thinking chain" technology to enable the model to reason and solve problems step by step. Practice has shown that through continuous trial and error, the performance of the model can be greatly improved by training the model from beginning to end (such as in games such as Go or Dota).
In addition, although o1 technology is still in the early stages of development, it has performed well in terms of security. For example, by enhancing the model's in-depth reasoning about the strategy, its robustness to adversarial attacks and reducing the risk of hallucination phenomena can be improved. This deep reasoning ability has begun to show positive results in security assessments.
"We developed a new model based on the o1 model, allowing it to participate in the 2024 International Olympiad in Informatics (IOI) competition and scored 213 points in 49% of the rankings." OpenAI said.
It competed under the same conditions as human contestants, solving six algorithmic problems, with 50 submission opportunities for each problem. By screening multiple candidate solutions and selecting submission solutions based on public test cases, model-generated test cases, and scoring functions, the effectiveness of its selection strategy was demonstrated, with an average score higher than that of random submissions.
When the number of submissions was relaxed to 10,000 per question, the model performed better and scored above the gold medal standard. Finally, the model demonstrated "amazing" performance in the simulated Codeforces programming competition.
"Sigh" coding ability. GPT-4o has an Elo rating of 808, which is in the 11th percentile of human competitors. Our new model has an Elo rating of 1807, which outperforms 93% of competitors.
Further fine-tuning in programming competitions improves the performance of the o1 model, source: OpenAI
OpenAI senior management changes
Before the release of o1, OpenAI has been mired in the shadow of changes in the company's core senior management.
In February of this year, Andrej Karpathy, a founding member and research scientist of OpenAI, announced at X that he had left the company. Karpathy said he left OpenAI amicably, "not because of any specific event, problem or drama."
Former chief scientist and co-founder Ilya Sutskevi (Ilya Sutskevi) Sutskever announced his resignation in May, and the super alignment team was disbanded. The industry believes that this is a failed attempt by OpenAI to balance the pursuit of technological breakthroughs and ensuring AI safety.
Hours after Ilya issued the announcement, Jan Leike, one of the inventors of RLHF and co-director of the super alignment team, followed in his footsteps and left, adding more uncertainty to the future of OpenAI.
In August, John Schulman, co-founder and research scientist of OpenAI, revealed his resignation and joined Anthropic to focus on in-depth research on AI alignment. He explained that his resignation was to focus on AI alignment and technical work, not because OpenAI did not support alignment research. Schulman thanked his colleagues at OpenAI and was "confident" in its future development.
Anthropic was founded by Dario Amodei, vice president of research at OpenAI, who left in 2020, and Daniela Amodei, then vice president of security and policy. Amodei brother and sister.
Brockman also announced a year-long leave in the same month, which was his "first long vacation" since he co-founded OpenAI nine years ago.
On September 10, Alexis Conneau, who led the audio interaction research of OpenAI GPT-4o and GPT-5 models, announced his resignation and started a business. Conneau's research is committed to achieving the natural voice interaction experience shown in the movie "Her", but the release of related products has been repeatedly delayed.
Since its establishment, OpenAI has attracted much attention for its dual identity of non-profit and commercialization. As the commercialization process accelerates, internal tensions about its non-profit mission have become increasingly apparent, which is also a reason for the loss of team members. At the same time, Elon Musk's recent lawsuit may also be related to the loss of personnel.
OpenAI researcher Daniel Kokotajlo said in an exclusive interview with the media after leaving that in the "palace fight" incident last year, Altman was briefly fired and quickly reinstated, and three board members focusing on AGI safety were replaced. "This has further consolidated power for Altman and Brockman, while marginalizing those who are primarily concerned with AGI safety. (Altman) They have deviated from the company's plan for 2022."
In addition, OpenAI faces an expected loss of up to $5 billion, and operating costs of up to $8.5 billion, most of which are server rental and training costs. To cope with the high operating pressure, OpenAI is seeking a new round of financing, with a valuation of more than $100 billion. Potential investors such as Microsoft, Apple and Nvidia have expressed interest. Company executives are seeking investment worldwide to support its rapidly growing funding needs. In order to ease financial pressure, OpenAI is seeking a new round of financing.
According to the New York Times on the 11th, OpenAI also hoped to raise about $1 billion at a valuation of $100 billion last week. However, because the computing power required to build large AI systems will lead to greater expenses, the company recently decided to increase its financing amount to $6.5 billion. However, foreign media quoted insiders and undisclosed internal financial data analysis as saying that OpenAI may face a huge loss of up to $5 billion this year, and total operating costs are expected to reach $8.5 billion. The cost of renting servers from Microsoft was as high as $4 billion, and the cost of data training was $3 billion.
As more advanced models such as Strawberry and Orion have higher operating costs, the company's economic pressure has further increased.
Tencent RTC Conversational AI Solutions
Tencent RTC Conversational AI Solutions are cutting-edge products that combine real-time communication technology with advanced artificial intelligence to create seamless, interactive experiences. These solutions leverage Automatic Speech Recognition (ASR), Text-to-Speech (TTS), Large Language Models (LLM), and Retrieval-Augmented Generation (RAG) to enable natural, intelligent conversations across various applications. From educational tools and virtual companions to productivity assistants and customer service enhancements, Tencent's offerings provide ultra-low latency, emotionally intelligent interactions, and customizable knowledge bases.
Use conversational AI to provide a more personalized educational experience
- AI Speaking Coach
- AI Virtual Teacher
- Character Dialogue
- Scenario Practice
Integrating voice capabilities allows for the creation of virtual teaching assistants that mimic real-time human interaction, providing personalized instruction and responsive feedback within educational scenarios.
Elevate social interactions and entertainment experiences with conversational AI
- Virtual AI Companion
- Character AI Dialogue
- Interactive Game
- Metaverse
Utilizing conversational AI combined with real-time interaction capabilities to understand user intentions and provide corresponding feedback, delivering a more realistic and personalized social entertainment experience for users.
Streamline workflows and boost efficiency with conversational AI
- Voice Search Assistant
- Voice Translation Assistant
- Schedule Assistant
- Office Assistant
Voice-activated productivity tools enable users to command and control applications with their voice, increasing efficiency and reducing manual input.
Elevate call center operations with conversational AI
- AI Customer Service
- AI Sales Consultant
- Intelligent Outbound Calling
- E-commerce Assistant
Conversational AI in call centers, powered by RAG and voice interaction, provides a rich, real-time customer service experience. It reduces costs and enhances service efficiency.
Why Choose Tencent RTC Conversational AI Solutions?
- Achieve Natural Dialogue with AI: Achieve Natural Dialogue with AI ASR + TTS technology ensures clear speech recognition and precise text-to-speech output, with a variety of voice options for a personalized communication experience.
- Ultra-low Latency Communication: Ultra-low Latency Communication Global end-to-end latency for voice and video transmission between the model and users is less than 300ms, ensuring smooth and uninterrupted communication.
- Deliver Precise and Stable Conversational AI: Deliver Precise and Stable Conversational AI LLM + RAG integration allows users to upload their knowledge bases to reduce misinformation and achieve more targeted and stable conversational AI.
- Emotional Communication Experience: Emotional Communication Experience Sentiment analysis and interruption handling accurately recognize and respond to user emotions, providing an emotionally rich communication experience.
Conclusion
I feel that Prompt may have to be explored again in the future. In the era of fast thinking and large models represented by GPT, we have a lot of so-called step-by-step thinking and other things, which are now all invalid and even have negative effects on o1.
The best way to write it given by OpenAI is:
- Keep prompts simple and direct: Models are good at understanding and responding to short, clear instructions without a lot of guidance.
- Avoid chain of thought prompts: Since these models reason internally, there is no need to prompt them to "think step by step" or "explain your reasoning."
- Use delimiters to improve clarity: Use delimiters such as triple quotes, XML tags, or section titles to clearly indicate different parts of the input and help the model interpret different parts appropriately.
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, only the most relevant information is included to prevent the model from over-complicating its response.
Finally, I want to talk about the length of this thinking. Now o1 thinks for one minute, but if it is a real AGI, to be honest, the slower the thinking, the more exciting it may be. What if he can really prove mathematical theorems, develop cancer drugs, and do astronomical research? How many hours, days, or even weeks can each thinking take? The final result may shock everyone beyond belief. Now, no one can imagine what AI will be like at that time.
And the future of o1, in my opinion, is definitely not just an ordinary ChatGPT.
It is the greatest cornerstone for us to move towards the next era. "There is no obstacle on our way to AGI." Now, I firmly believe this sentence without hesitation. The next era of starlight.
Q and A
Q1: What is the OpenAI o1 model?
A1: The OpenAI o1 model is a new AI model designed to think deeply and methodically, much like a human. It excels in complex reasoning tasks and has applications across various fields.
Q2: How does the o1 model differ from previous models?
A2: Unlike previous models, the o1 model takes its time to generate responses, allowing it to develop a comprehensive internal thought process and explore different strategies.
Q3: What are the key features of the o1 model?
A3: Key features include enhanced reasoning capabilities, applications in scientific and mathematical fields, and three variants tailored to different needs.
Q4: How can I access the o1 model?
A4: The o1-preview and o1-mini models are available to ChatGPT Plus and Team users. The main o1 model is not yet publicly available.
Q5: What are the pricing details for the o1 model?
A5: The o1-preview model costs 15permillioninputtokensand 60 per million output tokens. The o1-mini model is priced at 3permillioninputtokensand 12 per million output tokens.


